Wissens-Erzeugung in Visual Analytics
DFG Projekt im Bereich "Wissens-Erzeugung in Visual Analytics" (Mai 2017 bis 2020)
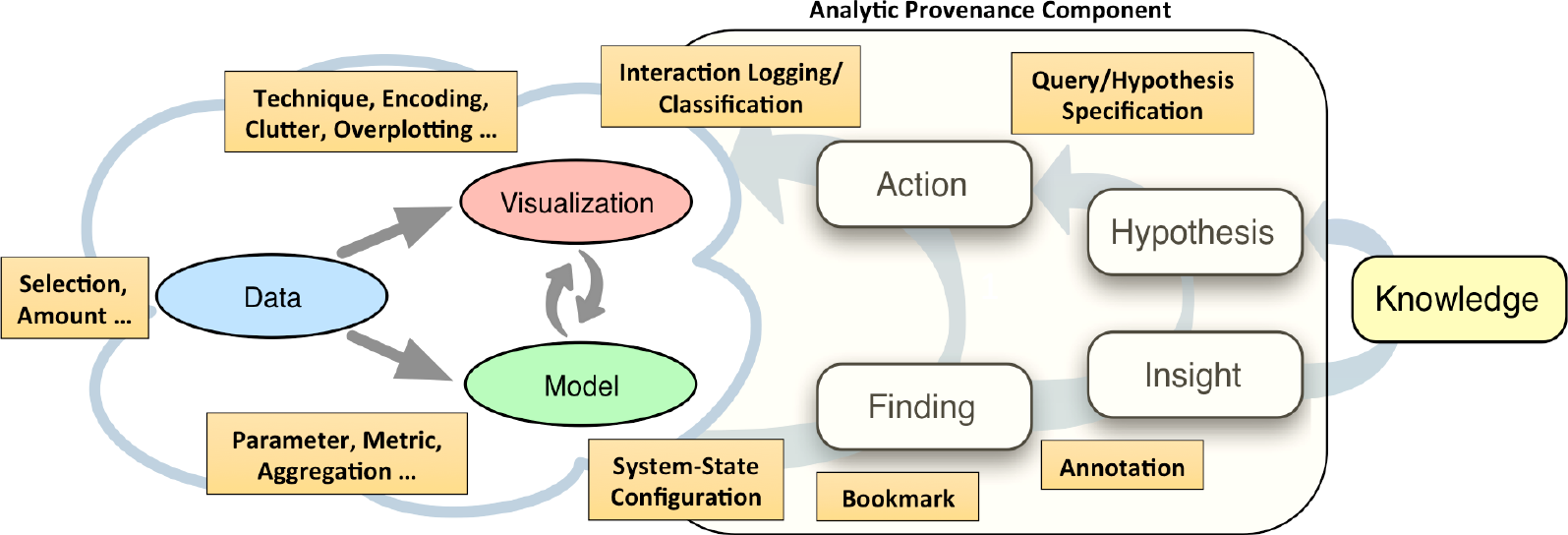
Visual Analytics (VA) vereint menschliche und maschinelle Fähigkeiten, um Wissen aus Daten zu erzeugen. Automatisierte Systeme sind in der Lage große Datenmengen zu verarbeiten, während Menschen komplexe Schlüsse ziehen und dabei auf ihr Allgemeinwissen zurückgreifen. Am VA Prozess sind Menschen für das interaktive Steuern und Kontrollieren der analytischen Verfahren verantwortlich.
Die meisten aktuellen Ansätze haben jedoch zwei wesentliche Nachteile:
- Einerseits können die Analysten ihr Expertenwissen während des Analyseprozesses nicht externalisieren;
- andererseits verstehen sie die Prozesse, die im System ablaufen, nur unzureichend.
Das vorliegende Projekt hat das Ziel, das Zusammenspiel von Mensch und Maschine im VA Prozess zu verbessern, um eine effektivere und effizientere Datenanalyse zu ermöglichen.
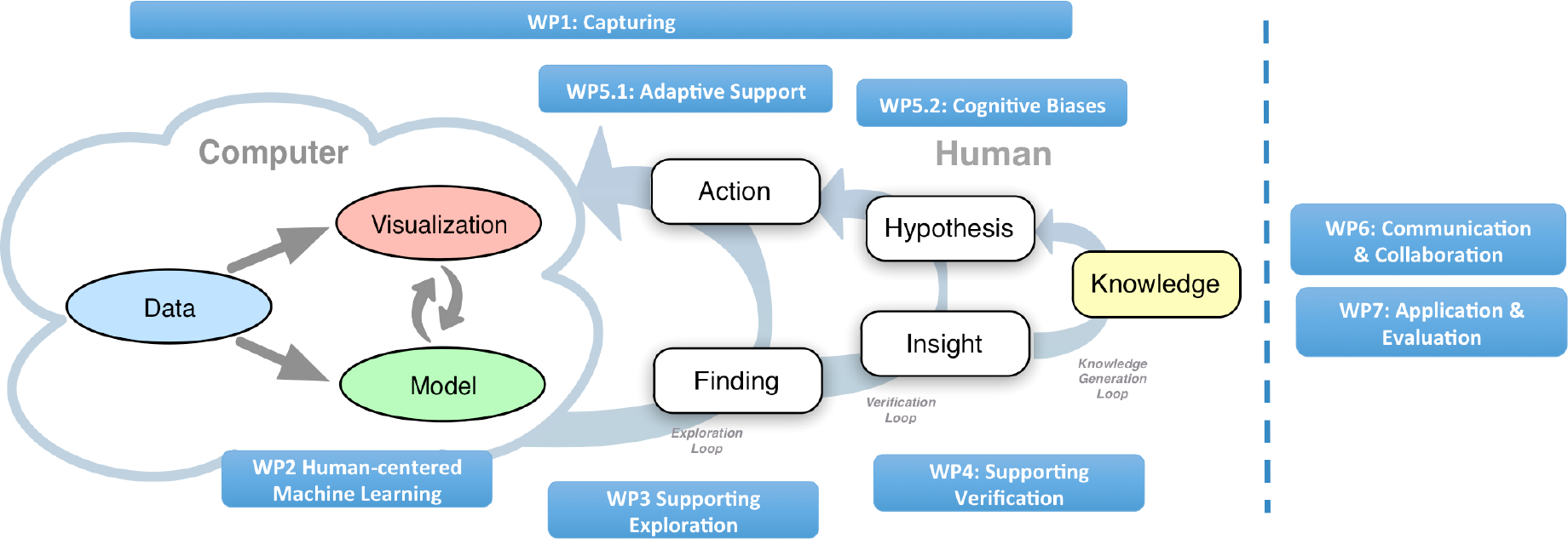
Dies wird durch das Zusammenführen von Daten und Analyse-Provenienz mit automatisierten und visuellen Methoden erreicht. Die Erfassung aller Datenverarbeitungs- und Analyseschritte werden dazu verwendet, die menschlichen Wissens-Erzeugungsprozesse an die individuellen Bedürfnisse der Benutzer anzupassen und während der Analyse zu unterstützen und zu automatisieren. Dabei soll die Lücke zwischen menschlicher Interaktion und maschinellem Lernen (ML) geschlossen werden, um komplexe Modell-Konfigurationen und Interaktionen damit zugänglich und benutzbar zu machen.
Darüber hinaus sollen menschliche Befangenheiten und Fehler während des Analyseprozesses, die durch kognitive Täuschungen (Cognitive Biases) entstehen, entdeckt und verhindert werden. Die Maschine kann hierbei als unbefangenes Gegenüber eingesetzt werden. Das einzigartige Merkmal dieses Forschungsantrags ist die ganzheitliche Betrachtung des Wissens- Erzeugungsprozesses mit der Zielsetzung, den aktuellen Forschungsstand durch das Entwickeln und Verknüpfen von Verfahren entlang der gesamten VA-Verarbeitungskette zu verbessern.
Die erforschten Verfahren werden auf mehrere echte Datensätze, Domänen, Aufgaben und Benutzer aus den Analysebereichen von Flugverkehr-Trajektorien, politischen Diskussionen und Subspace Clustering in hoch-dimensionalen Daten angewandt. Der Nutzen dieser Forschung wird durch Benutzerstudien evaluiert, welche die Vorteile der neuartigen Verfahren, den Datenanalyse-Prozess zugänglicher, effektiver, effizienter, transparenter und verlässlicher zu machen, demonstrieren.